[혼공R이] 1주차_작업환경이 이뻐야 공부도 잘 되는 법
[혼공R이] 2주차_게더타운으로 외로움을 달래며 손코딩
[혼공R이] 4주차_구정 연휴에 몰아서 다 끝내버릴 수 있을까?
[혼공R이] 6주차 1편_황금같은 토요일 아침 adsp 털리고 와서 몰아치는 중


header 옵션
header = TRUE : 파일의 첫 번째 행을 열 이름(헤더)로 처리한다.
header = FALSE : 파일의 첫 번째 행을 데이터로 처리하고, 기본 열 이름(예 : V1, V2, ...)을 자동으로 생성한다.
encoding과 fileEncoding 옵션
이 두 옵션은 주로 데이터의 텍스트가 깨지거나 잘못 해석되지 않도록 하는 역할을 한다.
encoding 옵션 : 텍스트 데이터가 읽히거나 출력될 때 문자열을 어떻게 해석할지 지정.
fileEncoding 옵션 : 파일의 문자 인코딩을 지정하여 파일에서 데이터를 읽거나 파일에 데이터를 저장할 때 사용하는 인코딩을 설정.

외부 데이터 가져오기 : TXT 파일
read.table("원시 데이터", header = FALSE, skip = 0, nrows = -1, sep = "", . . .)
header : 데이터 파일의 첫 번째 행이 열 이름인지 여부를 지정. 기본값은 FALSE
skip : 건너뛸 행의 수를 지정
nrows : 읽을 행의 수를 지정, 기본값은 -1(파일의 끝까지)
sep : 열 데이터를 구분하는 구분자 지정, 기본값은 ""(임의의 공백)

외부 데이터 가져오기 : CSV 파일
read.csv() 함수는 따로 옵션을 설정하지 않아도 원시 데이터의 1행을 변수명으로 가져온다. 만약 값이 비어 있다면 임의로 지정된다.
외부 데이터 가져오기 : 엑셀 파일
readxl 패키지 설치 및 로드하기
install.pakages('readxl')
library(readxl)
read_excel() 함수는 기본값으로 첫 번째 시트 탭의 데이터를 가져온다.
만약 시트탭이 여러 개여서 첫 번째 외의 다른 탭 시트 데이터를 가져오려면 sheet 옵션을 사용한다.
sheet 옵션에는 가져올 시트가 몇 번째인지 위치를 입력한다.
sheet = 2를 지정하면 두 번째 시트 데이터를 가져온다.
외부 데이터 가져오기 : XML, JSON 파일
XML 파일 : HTML과 비슷하지만 데이터를 보여주는 것이 아닌 저장하고 전달하는 목적으로 만들어진 형식. HTML처럼 태그가 미리 정의되어 있지 않고 태그를 사용하자 직접 정의한다.
JSON 파일 : 데이터를 전달하는 목적으로 만들어진 파일 형식. 서버-클라이언트 통신 간 데이터를 받아 객체나 변수에 할당해서 사용할 때 많이 사용하며, XML 파일보다 구문이 짧고 속도가 빨라 실무에서 흔히 사용한다.
XML 파일 가져오기
xmlToDataFrame() 함수를 가장 많이 사용한다.
XML 패키지 설치 및 로드하기
install.pakages("XML")
libaray(XML)
JSON 파일 가져오기
JSON 파일은 데이터 안에 다시 데이터가 정의된 중첩된 데이터구조로 이루어져 있다.
데이터 속성과 값이 쌍으로 이루어진 것이 특징.
fromJSON() 함수 사용.
jsonlite 패키지 설치 및 로드하기
install.packages("jsonlite")
libarary(jsonlite)
fromJSON() 함수는 JSON파일을 데이터 프레임으로 가져오는 함수가 아니다.
따라서 실행 결과는 View() 함수가 아닌 str() 함수로 구조를 살펴본다.

fromJSON() 함수는 JSON 파일이나 JSON 형식의 문자열을 R 객체로 변환하는 함수이다.
만약 JSON이 2차원 배열 형태이면 데이터 프레임으로 변환될 수 있다.
만약 JSON이 중첩된 구조라면 리스트로 변환된다.
따라서 fromJSON()의 결과는 데이터 프레임이 아닐 수 있으므로 str()로 구조를 확인한다.
str() 함수는 R에서 객체의 구조를 간단히 보여주는 함수이다.
객체가 가진 데이터의 타입, 크기, 구성 요소 등을 한눈에 확인할 수 있다.
이는 특히 데이터 구조를 탐색하거나 디버깅할 때 유용하다.
데이터 전체 확인하기
내장 데이터 세트 : R 에서 기본 제공
data() 함수
데이터 요약 확인하기
str() 함수 : 데이터 구조 확인하기
ncol() 함수 : 데이터 프레임 컬럼(열) 개수 확인하기
nrow() 함수 : 데이터 프레임 관측치(행) 개수 확인하기
dim() 함수 : 데이터 프레임 컬럼(열) 및 관측치(행) 개수 확인하기
length() 함수 : 데이터 길이 출력(벡터의 데이터 개수 확인, 데이터 프레임 열의 개수 확인, 혹은 데이터 프레임의 특정 열을 선택하면 행의 개수도 확인할 수 있다.)
ls() 함수 : 컬럼명 확인
head() 함수 : 데이터의 앞부분 값을 확인, 기본값 6개
tail() 함수 : 데이터의 뒷부분 값을 확인, 기본값 6개
기술통계량 확인하기
기술통계량 : 데이터를 요약한 대푯값
데이터 프레임명$변수명 : 데이터 프레임 내 특정 변수(열)에 접근할 때 사용
mean() 함수 : 평균을 구한다.
median() 함수 : 중앙값을 구한다.
min() 함수 : 최솟값을 구한다.
max() 함수 : 최댓값을 구한다.
range() 함수 : 범위를 구한다.
분위수 : 전체 데이터를 크기 순으로 정렬하여 n개로 나누었을 때 그 경계에 해당하는 값
사분위수 : 데이터를 4등분 한 지점의 관측값
제1사분위수(Q1) : 제 0.25분위수, 하위 25%에 해당하는 값
제2사분위수(Q2) : 제 0.50분위수, 50%에 해당하는 값
제3사분위수(Q3) : 제 0.75분위수, 하위 75% 혹은 상위 25%에 해당하는 값
제4사분위수(Q4) : 제 1분위수, 100%에 해당하는 값
quantile() 함수 : 분위수를 구한다.
quantile(변수명, probs = 0 ~1)
probs 옵션을 지정하면 제1사분위수, 제2사분위수, 제3사분위수를 출력한다.
산포도 : 데이터가 대푯값에서 어느 정도 흩어져 있는지
분산 : 데이터가 평균으로부터 퍼진 정도를 설명하는 통계량, 값이 클수록 평균에서 데이터 값이 퍼진 정도가 넓다.
표준편차 : 데이터 값이 퍼진 정도를 설명하는 통계량
var() 함수 : 분산을 구한다.
sd() 함수 : 표준편차를 구한다.
첨도 : 데이터 분포가 정규분포 대비 뾰족한 정도를 설명하는 통계량, 데이터가 어느 정도로 중심에 몰려 있는지 파악할 수 있다.
첨도는 통계량이 0보다 크면 정규분포 대비 그래프 곡선이 뾰족하며, 0보다 작으면 정규분포 대비 그래프 곡선이 완만하다.
왜도 : 데이터 분포의 비대칭선을 설명하는 통계량, 데이터가 어느 방향으로 치우쳐 있는지 또는 대칭을 띄고 있는지 파악할 수 있다.
왜도 값이 0에 가까울수록 좌우대칭, 0보다 큰 경우 오른쪽 꼬리를 가지는 분포, 0보다 작은 경우 왼쪽 꼬리를 가지는 분포를 띄고 있다.
kurtosis() 함수 : 첨도를 구한다.
skew() 함수 : 왜도를 구한다.
첨도와 왜도 함수를 사용하려면 psych 패키지가 필요하다.
install.packages("psych")
library(psych)
데이터 빈도분석하기
빈도분석 : 데이터의 항목별 빈도 및 빈도 비율을 나타내는 방법으로 데이터 분포를 파악할 때 가장 많이 사용하는 분석 기법
빈도분석에는 주로 freq() 함수 사용
freq() 함수는 descr 패키지에 포함되어 있다.
install.packages("descr")
library(descr)

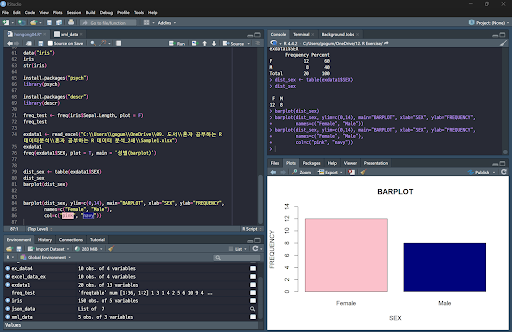
막대 그래프 그리기
막대 그래프 : 범주형 데이터의 수량이 많고 적음을 나타낼 때 적합한 그래프로, 각 항목의 수량을 빠르게 파악할 수 있다.
freq() 함수 : 데이터 빈도 분포를 확인하며 plot 옵션을 설정하면 막대 그래프를 출력할 수 있다.

barplot() 함수 : 별도의 패키지를 설치하지 않아도 막대 그래프를 그릴 수 있다. (빈도 분포를 구하는 기능이 없다.)
barplot(변수명, ylim = c(y축 범위), main = "그래프 제목", xlab = "x축 제목", ylab = "y축 제목", names = c("컬럼 제목", . . . ), col = c("색상", . . .), . . .)
table() 함수 : 표 형태로 데이터가 구성되어 있을 때 변수별로 빈도를 표현할 수 있다.
freq() 함수는 빈도와 비율, 전체 합계를 출력하며 항목 값을 세로로 표현하는 반면 table() 함수는 항목 값을 가로로 나열한다.
상자 그림 그리기
boxplot() 함수 : 상자 그림을 그린다.

히스토그램 그리기
히스토그램 : 연속형 데이터를 일정하게 나눈 구간(계급)을 가로 축으로, 각 구간에 해당하는 데이터 수(도수)를 세로 축으로 그린 그래프
hist() 함수 : 히스토그램을 그린다.

파이차트 그리기
파이차트 : 원을 데이터 범주 구성 비례에 따라 파이 조각을 나누는 것처럼 표현하는 그래프
pie() 함수 : 파이차트를 출력한다.
pie() 함수에는 빈도분석 기능이 없으므로 먼저 빈도분석을 하는 table() 함수를 실행한다.

줄기 잎 그림 그리기
줄기 잎 그림 : 변수 값을 자릿수로 분류하여 시각화하는 방법으로, 큰 자릿수의 값은 줄기에 표현하고 작은 자릿수의 값은 잎에 표현하여 데이터의 전체적인 형태를 파악할 수 있는 그래프이다.
stem() 함수 : 줄기 잎 그림을 출력한다.
stem(변수명, scale = 1)
scale 옵션은 줄기의 수, 즉 데이터를 나누는 구간을 의미하며 양수만 가능하다.
scale 숫자가 커질수록 줄기 수가 늘어나고 작을수록 줄어들기 때문에 데이터에 따라 scale을 조절하면 데이터 분포를 쉽게 파악할 수 있다.
산점도 그리기
산점도 = 산포도
plot() 함수 : 산점도를 출력한다.
plot(x, y)
산점도 행렬 : 산점도들이 행렬도 나타나며 여러 개의 변수 관계를 한번에 확인할 수 있는 그래프
pairs() 함수 : 산점도 행렬을 출력한다.

산점도 행렬은 psych 패키지의 pairs.panel() 함수로도 그릴 수 있다.
사용 형식은 pairs() 함수와 동일하지만, 함수 실행 전에 psych 패키지 설치와 로드가 필요하다.

[기본 숙제(필수)]
p. 169의 iris 내장 데이터 세트의 데이터 구조 출력하고 인증하기

[추가 숙제(선택)]
p. 191 상자 그림 그래프의 각 요약 값 정리하기

최소값, 제1사분위수, 중앙값, 제3사분위수, 최대값, 이상치
boxplot() 함수에서 직접 요약값을 확인하려면 boxplot.stats() 함수를 사용하면 된다.
# Y21_CNT의 박스플롯 요약값
boxplot.stats(exdata1$Y21_CNT)
# Y20_CNT의 박스플롯 요약값
boxplot.stats(exdata1$Y20_CNT)

$stats
[1] 10.0 17.5 25.0 32.5 40.0 # Min, Q1, Median, Q3, Max
$n
[1] 7 # 데이터 개수
$out
numeric(0) # 이상치가 없는 경우

![[한글흘림체필사] 도보순례_이문재](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjPTzu1H9Kvb_WlnlKeQ0R__Ck99-Wz88jQBuXbVfjDuhaLr0O10exwZhDhIHVN5DRhiWo2IvLby77YDMu9EmJfseMZ8_kHzDWDLm0cDMQ0lLOGMLRWCRDy4meq0znNo7wmZDaTON1JgMI/w680/1578727237905233-0.png)

![[한글흘림체필사] 용기_요한 괴테](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEghKtQs7Zx_SG4605k-06iCfhKJE3UdSj3GR7r938GsbMgEwqPq7_XsDVnUHqiOS3VgjN21vU_Z_7mS1SrDw5XgrWfsXjMLwEDWMB6RVGDndOwtla3JZfClHfLHwNZyBKAnprnXQ4LKOiY/w680/1578717214648019-0.png)

{kind=link}
0 댓글