[혼공R이] 1주차_작업환경이 이뻐야 공부도 잘 되는 법
[혼공R이] 2주차_게더타운으로 외로움을 달래며 손코딩
[혼공R이] 4주차_구정 연휴에 몰아서 다 끝내버릴 수 있을까?
[혼공R이] 6주차 1편_황금같은 토요일 아침 adsp 털리고 와서 몰아치는 중
dplyr 패키지
해틀리 위컴이 만든 데이터 처리 패키지
R로 개발되어 처리 속도가 느린 기존의 plyr 패키지를 C++ 언어로 개선하여 사용자 친화적으로 데이터 프레임을 조작할 수 있다.
install.packages("dplyr")
library(dplyr)
:: 더블 콜론 연산자
다른 패키지에 동일한 함수가 있을 때 특정 패키지 임을 표시
데이터 추출 및 정렬하기
filter() 함수 : 행 추출하기, 조건에 맞는 데이터를 필터링하는 함수
select() 함수 : 열 추출하기, 지정한 변수만 추출
arrange() 함수 : 데이터를 오름차순으로 정렬할 때 사용
decs() 함수 : 데이터를 내림차순으로 정렬할 때 사용
데이터 추가 및 중복 데이터 제거하기
mutate() 함수 : 데이터 세트에 열을 추가할 때 사용한다.
distinct() 함수 : 중복 값을 제거할 때 사용, 중복 값을 제거하면 해당 열이 총 몇 가지 관측치로 구성되어 있는지 한눈에 확인할 수 있다.
데이터 요약 및 샘플 추출하기
summarise() 함수 : 기술통계 함수와 함께 사용하여 데이터 요약을 확인할 때 사용
summarise() = summarize()
summarise(데이터, 요약할 변수명 = 기술통계 함수)
group_by() 함수 : 그룹별로 데이터를 요약할 때 사용
n() 함수 : 데이터 개수를 구한다.
n_distinct() 함수 : 특정 열의 중복 값을 제외하고 개수를 파악
sample_n() 함수 : 전체 데이터에서 샘플 데이터를 개수 기준으로 추출한다.
sample_frac() 함수 : 전체 데이터에서 샘플 데이터를 비율 기준으로 추출한다.
파이프 연산자 : %>%
파이프 연산자 : 연결하여 연산하는 연산자
데이터 세트 %>% 조건 또는 계산 %>% 데이터 세트
%>% 연산자를 사용하면 함수를 연달아 사용할 때 함수 결괏값을 변수로 저장하는 과정을 거치지 않아도 된다.
값을 받아 함수로 바로 이어서 사용할 수 있기 때문에 전체 코드가 간결해져 가독성이 좋아진다.
단축키 : [Shift] + [Ctrl] + [M]
데이터 가공
데이터를 분석할 때 변수를 생성하거나 변수명을 변경하고, 조건에 맞는 데이터를 추출하거나 변경하고, 데이터를 정렬하고 병합하는 일련의 과정
= 데이터 전처리 = 데이터 핸들링 = 데이터 마트


데이터 결합하기
결합 : 2개 이상의 테이블을 결합하여 하나의 테이블로 만드는 과정
세로 결합 : 결합할 테이블에 있는 변수명을 기준으로 결합, 각 테이블에 서로 다른 변수도 결합하는 테이블에 추가
가로 결합 : 테이블 결합 기준이 되는 by = "변수명" 에 사용될 변수(키)가 필요.
기 변수는 결합할 각 테이블에 있어야 하며 한쪽이라도 키 변수가 없으면 실행되지 않는다.
bind_row() 함수 : 세로 결합
left_join() 함수 : 지정한 변수와 테이블 1을 기준으로 테이블 2에 있는 나머지 변수들을 결합
inner_join() 함수 : 테이블1과 테이블2에서 기준으로 지정한 변수 값이 동일할 때만 결합
full_join() 함수 : 테이블1과 테이블2에서 기준으로 지정한 변수 값 전체를 결합
데이터 재구조화
동일한 데이터가 있더라도 목적에 따라 분석 기준이 달라지며, 그에 따라 데이터 구조 변형
reshape2 패키지
reshape 패키지의 성능을 개선한 것
melt() 함수 : 열이 긴 형태의 데이터를 행이 긴 형태로 바꾼다.
melt(데이터, id.vars = "기준 열", measure.vars = "변환 열")
na.rm = FALSE : 결측치 포함 옵션
cast() 함수 : 행이 긴 형태의 데이터를 열이 긴 형태로 바꾼다.
acast() 함수 : 데이터를 변형하여 벡터, 행렬, 배열 형태로 반환한다.
dcast() 함수 : 데이터를 변형하여 데이터 프레임 형태로 반환한다.
names() 함수 : 변수명을 구한다.
tolower() 함수 : 소문자로 치환
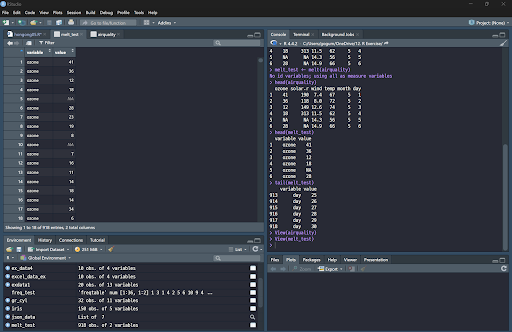
dcast() 함수
dcast(데이터, 기준 열 ~ 변환 열)
변수 두 개를 식별자로 지정할 때는 + 기호를 사용한다.
acast() 함수
acast(데이터, 기준 열 ~ 변환 열 ~ 분리 기준 열)
분리 기준 열은 출력되는 배열에서 차원을 추가하는 역할을 한다.
일반적으로 3차원 배열 형태로 변환되며, 각 차원의 슬라이스(부분)로 나뉜다.

데이터 정제하기
데이터 정제 : 결측치와 이상치를 처리하는 과정
Null : 아무것도 없음
NA(Not Available) : 결측치(결측값)
NaN : 비수치
is.na() 함수 : 결측치를 확인하여 결괏값을 TRUE 와 FALSE 로 반환
table(is.na()) 함수 : 결측치 빈도를 확인
결측치 제외하기
데이터에 결측치가 있으면 연산을 해도 결과가 NA로 나온다.
결측치를 제외하는 방법은 na.rm=T 옵션을 사용한다.
sum(is.na()) 함수 : 데이터 세트에 결측치가 총 몇 개인지 확인
colSums(is.na()) 함수 : 각 컬럼의 결측치 개수를 확인

결측치 제거하기
na.omit() 함수 : 결측치가 있는 행 전체를 데이터 세트에서 제거한 후 데이터를 출력한다.
결측치 대체하기
변수명[is.na(변수명)] <- 대체할 값

airquality[is.na(airquality)] <- 0 코드분석
✔ is.na(airquality)
airquality데이터셋에서NA가 있는 위치를TRUE/FALSE로 반환
✔ airquality[is.na(airquality)]
NA가 있는 위치만 선택
✔ <- 0
- 선택된
NA값을0으로 변경
이상치 확인하기
이상치(극단치) : 데이터에서 정상적인 범주를 벗어난 값을 의미
상자 그림을 통해서 쉽게 파악할 수 있다.
이상치 처리하기
ifelse() 함수 사용하여 이상치가 있을 때는 해당 값을 결측치로, 그렇지 않을 경우에는 원래의 값이 반환되도록 코드를 작성한다.
연산할 때 na.rm = T 옵션을 사용하거나 na.omit() 함수로 결측치를 제거하는 방법 등을 이용해서 결측치를 처리한 후에 데이터 분석을 한다.
[기본 숙제(필수)]
p. 244의 확인 문제 2번 풀고 인증하기

[추가 숙제(선택)]
p. 261 확인 문제 4번 풀고 인증하기

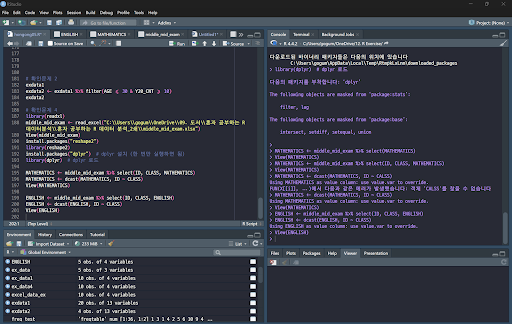
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 확인문제 4 library(readxl) middle_mid_exam <- read_excel("C:\\Users\\gogum\\OneDrive\\09. 도서\\혼자 공부하는 R 데이터분석\\혼자 공부하는 R 데이터 분석_2쇄\\middle_mid_exam.xlsx") View(middle_mid_exam) install.packages("reshape2") library(reshape2) install.packages("dplyr") library(dplyr) MATHEMATICS <- middle_mid_exam %>% select(ID, CLASS, MATHEMATICS) MATHEMATICS <- dcast(MATHEMATICS, ID ~ CLASS) View(MATHEMATICS) ENGLISH <- middle_mid_exam %>% select(ID, CLASS, ENGLISH) ENGLISH <- dcast(ENGLISH, ID ~ CLASS) View(ENGLISH) | cs |

![[한글흘림체필사] 도보순례_이문재](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjPTzu1H9Kvb_WlnlKeQ0R__Ck99-Wz88jQBuXbVfjDuhaLr0O10exwZhDhIHVN5DRhiWo2IvLby77YDMu9EmJfseMZ8_kHzDWDLm0cDMQ0lLOGMLRWCRDy4meq0znNo7wmZDaTON1JgMI/w680/1578727237905233-0.png)

![[한글흘림체필사] 용기_요한 괴테](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEghKtQs7Zx_SG4605k-06iCfhKJE3UdSj3GR7r938GsbMgEwqPq7_XsDVnUHqiOS3VgjN21vU_Z_7mS1SrDw5XgrWfsXjMLwEDWMB6RVGDndOwtla3JZfClHfLHwNZyBKAnprnXQ4LKOiY/w680/1578717214648019-0.png)

0 댓글